TokuMX使用小计
最近因为工作的缘故,接触了TokuMX,尝试下来感觉不错,值得介绍给大家。
事情的起因是要解决MongoDB的问题。系统中需要保存程序输出的运行信息,这类信息比程序语言的log更高级,但又不如业务操作日志高级,是某些时候发现问题的关键证据,所以必须保存。因为格式不太规范,又需要方便检索,所以文档型NoSQL的MongoDB是比较好的选择。
但是,选择MongoDB就必然会面对磁盘空间的问题。我们的数据大概是这样的:每天的数据量不到200万条,单条数据的平均大小不超过4k,但MongoDB存一个月的数据就消耗了接近40G,最近三个月的数据则需要接近100G。限于具体的硬件环境,只能保存最近三个月的数据,但这无法满足业务需求,所以必须另想办法。
最终我们选定的方案是TokuMX。它是一款开源的、高性能的MongoDB发布(distribution),在提供与MongoDB完全兼容的客户端、API的同时,号称可以减少90%的存储空间,同时提供20倍的性能提升。我也了解到,已经有一些生产系统在使用TokuMX,反馈不错(比如 这里 和 这里)。
经过我的测试,从MongoDB迁移到TokuMX非常简单:用mongodump将原有数据导出,再在安装了TokuMX的机器上mongorestore即可。原先用MongoDB需要102G的数据,采用默认的zlib压缩方式导入TokuMX之后,只有2.2G,同时导入速度大大提高(至少有10倍的提高),而查询性能没有降低(QPS在2位数左右,使用索引)。这个对比是我不敢想像的,它直接解决了现在的问题。
对着这份数据,我不免好奇TokuMX究竟使用了怎样的技术?就我现在的了解,减少磁盘空间占用主要是在存储层使用了压缩方式(TokuMX宣称,如果不使用压缩,TokuMX的磁盘占用也比MongoDB少10%左右)。这种思路不稀奇,5.x版本的MySQL中,如果设定file_format为Barracuda,也可以直接对表做压缩,同时外部操作不需要做任何变化。TokuMX的提高写入速度则相当有趣,按照TokuMX的做法是使用分形树索引(Fractal Tree Index),替代了所谓“已经有40年历史的B树索引”,按照Wiki上的说法,TokuMX是分形树索引进行商业应用的典型。
“分形”是一个数学上的概念,大略来说,指的是“事物的每一部分都近似整体缩小后的形状”。TokuMX的分形树索引,严格说起来更像“B树 + 批量写入”,与B树的不同在于,分形树的每个内部节点都带有自己的缓冲区,它存储尚未落实(pending)到叶子节点的数据,默认情况下写入只会到缓冲区,缓冲区填满之后会把所有的写操作刷(flush)下去。
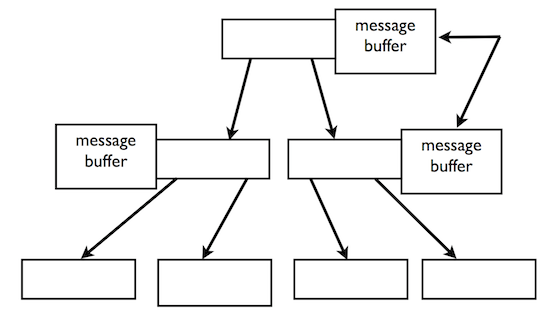
我顺手翻译了TokuMX的一篇介绍文章,供大家参考。
再附两份参考资料
percona的TokuDB和TokuMX介绍文档
http://www.percona.com/live/london-2013/sessions/fractal-tree-indexes-theory-practice
Facebook的人做的性能对比评测
http://smalldatum.blogspot.com/
推特上的 @BohuTang 应该是 TokuTek 的贡献者,人非常好,大家有问题也可以和他讨论。
From Life Sailor, post TokuMX使用小计
多谢分享!