beta技术沙龙:大型网站的Lucene应用
beta技术沙龙越办越有意思了,上次错过了阙宏宇的mod_cache(还有关于线程进程的讨论)就很可惜,这次关于Lucene的演讲,是无论如何不应该错过了。
到目前为止,全文检索已经完全不算高技术门槛了,记得以前看过一本书里面写:“今天,任何程序员,都可以很容易地构造一个全文检索应用”。是的,全文检索的基本原理大家都知道差不多了,剩下的只是实践。我见过纯粹自己开发的,具有AS(Advanced Search)、BS(Basic Search)、DI(Digest)等结构,“像模像样”的全文检索架构,不过应用更多的,却是在开源项目上完善、定制而来的,Apache的Lucene就是众多开源全文检索项目中,名气最大、资格最老、应用也最广泛的一个。本期beta技术沙龙,讲的就是大型网站中lucene的应用,主讲人是手机之家团队的唐福林(“手机之家”总是有些东东来共享,比如上次的DAL,这真是不错)。
众所周知,用Lucene构造一个“索引-查询”的应用是非常简单的,搭好环境,参照(修改)示范代码,很容易就可以成功。但是,要构造一个真正大规模、稳定、可靠的应用,就不说这么简单。程序的编写、模块的分布、架构的设计,都有许多费心思的讲究。按照PPT提供的数据,手机之家目前的Lucene应用,采用的是Lucene 2.4.1 + JDK 1.6(64 bit)的组合,运行在8 CPU, 32G内存的机器上,数据量超过3300万条,原始数据文件超过14G,每天需要支持超过35万次的查询,高峰时期QPS超过20。单看这些数据可能并没有大的亮点,但它的重建和更新都是自动化完成,而且两项任务可以同时运行,另一方面,在不影响服务可靠性的前提下,尽可能快地更新数据(如果两者发生冲突,则优先保证可用性,延迟更新),其中的工作量还是非常大的。
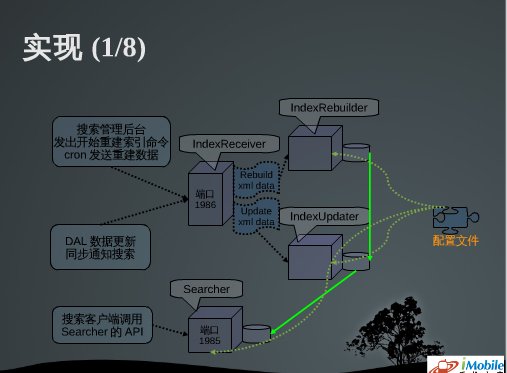
演讲的主要内容都PPT里,非常丰富,我就不再赘述了。要补充的是,这份PPT做得非常清楚,需求-目标-进度-设计-上线-测试-上线,整个流程非常清楚,给出的数据同样非常精当,我想,这也反映了手机之家团队的开发规范。
因为对Lucene的使用稍微有些经验,我在这里补充几句,权当狗尾续貂:
- 在大规模的应用中,Lucene更适合用于狭义的“搜索”,而不应当负责数据的存储。我们看看Lucene的源代码也可以知道,Document和Field的存储效率是不够好看的。手机之家的团队也发现了这一点,他们的办法是,用Lucene存放索引,用Memcache + Berkeley DB(Java Edition)负责存储。这样有两个好处,一是减小了Lucene的数据规模,提高了程序的效率;另一方面,这套系统也可以提供某些类似SQL的查询功能。实际上,Lucene Project自己似乎也注意到了这个问题,在Store中新增了一个db选项,其实也是利用的Berkeley DB。如果仅仅用Lucene存放索引,而不存放Document,并且合理配置,一台机器可以支持几十G甚至上百G的索引;如果需要用Lucene存放索引,最好在读取时使用FieldSelector,只读取需要的Field,如果使用恰当,性能会有10%左右的提升。
- 在大规模应用中,Cache是非常重要的。PPT中也提到,可以在程序提供服务之前,进行几次”预热“搜索,填充Searcher的Cache。据我们(银杏搜索)的经验,也可以在应用程序中,再提供针对Document的Cache,这样对性能有较大的改善(同一个JVM内部的Cache,速度更快一些)。Lucene自己似乎也注意到了这个问题,在2.4版本中提供了Cache,并提供了一个LRU Cache实现。不过据我们测试,在极端情况下,这个Cache可能会突破大小限制,一路膨胀最后吃光内存,甚至从网络上找的许多LRU Cache实现在极端条件下都有可能出现这样的问题(这也是我们百思不得其解的地方:反复检查程序的逻辑都没有问题),最终自己写了一个LRU Cache,并修改多次,目前来看是稳定的。
- 在编写Java服务程序的时候,记得设置退出的钩子函数(RunTime.getRunTime.addShutdownHook)是一个非常好的习惯。许多Java程序员都没有这种意识,或者有,也只是写一个finalize函数,结果程序非正常退出时,可能造成某些外部资源的状态不稳定。拿Lucene来说,之前的IndexWriter是默认autoCommit的,这样每添加一条记录,就提交一次,好处是如果中断,则之前添加的记录都是可用的,坏处则是,索引的速度非常低。在新版本中autoCommit默认为False,速度提升明显(我们测试的结果是,提高了大约8倍),但如果中途异常退出,则前功尽弃。如果我们添加了退出的钩子函数,捕获到退出信号则自动调用writer.close()方法,就可以避免这个问题。
- 目前的Lucene是兼容JDK 1.4的,它的binary版本也是JDK1.4编译的,如果对性能要求比较高,可以自行下载Lucene Source Code,用更新版本的JDK编译出.jar文件,据我测试,速度大约有30%的提升。
- 如果对并发的要求较高,可以考虑采用多IndexSearcher的技术,也就是在一个应用服务中,开启多个IndexReader(可以对同样的索引开启多个),每个IndexReader再生成一个IndexSearcher,将这些Searcher放在一个“池”里头,给搜索请求调用。这样可以大幅度提高并发的性能,代价是在写程序的时候就要考虑到这一点,进行相应的调整。
P.S. 据我观察,国内公司内部的项目,一般取的名字都中规中矩,以’er’结尾的比较多,多是Indexer, Crawler, Layer之类。好像很少有外国那种“天马行空”的奇特名字,譬如Hadoop(这是一个“没来由”的名字)、Lucene(这是个少见的姓)。国内我接触过不多,以前抓虾有个重要的DB叫tudui(“土堆”),目前银杏有个项目叫LaserTank,都是跟实际用途毫不相关的,印象反而深刻。